Urgent Info
- There is no Urgent Info now.



GSIC
| Addr. | 2-12-1 O-okayama, Meguroku, Tokyo 152-8550 JAPAN |
| Contact this mail address. |
You are here
JHPCN: Application examples for very large-scale data processing and very large capacity network technology
GSIC, Tokyo Institute of Technology
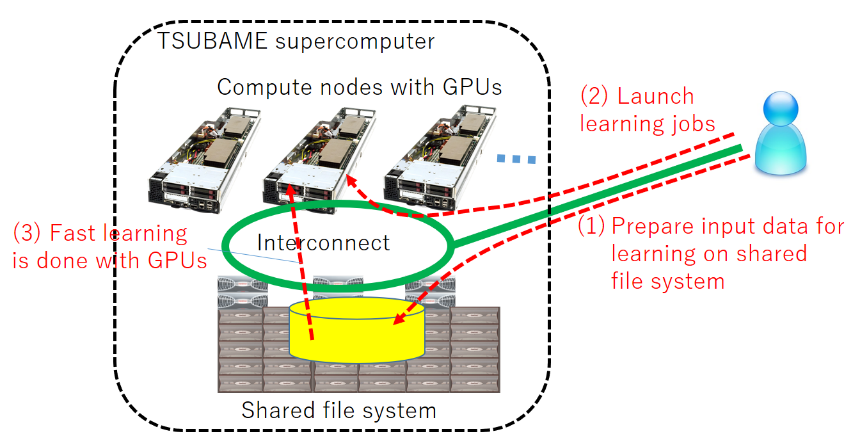
Machine learning jobs, especially in deep learning which recently attracts great attention, require both storage resources for storing large scale I/O data and high performance computation resources. For these jobs, we provide environment for large-scale high-performance machine learning by using lots of GPUs (>4,000 in the whole system) and storage (up to 30TB per user group) equipped by the TSUBAME2.5 supercomputer. By using pre-installed frameworks that harnesses GPUs, acceleration of research projects of large scale machine learning is expected.
Moreover, new TSUBAME3.0 supercomputer, which will be available in August 2017 (as of planned), will provide higher performance and larger storages for jobs including machine learning jobs.
Available Resources
[Hardware]
Refer to description of TSUBAME2.5 in Appendix 1. Especially, 3 Tesla K20X GPUs per node are available.
(We plan to provide resources on the successor machine of TSUBAME2.5 in August 2017 and later)
[Software]
Refer to description of TSUBAME2.5 in Appendix 1. The followings are highly related items to this page:
- OS: SUSE Linux 11SP3
- Programming Languages: Python2, Python3, Java, R
- Application software: Caffe, Chainer, Theano, TensorFlow
(Currently these frameworks are maintained by research staffs, and some functions may be restricted.)
Resource Usage
TSUBAME2.5
Same as regular usage.