Urgent Info
- There is no Urgent Info now.



GSIC
| Addr. | 2-12-1 O-okayama, Meguroku, Tokyo 152-8550 JAPAN |
| Contact this mail address. |
You are here
Booth Talk Schedule
| SC17 TOP | News Release | Presentations | Booth Talk Schedule | Booth Posters | Booth Map | Photo Gallery |
Nov. 13th Mon. 7:30PM - 8:00PM

TSUBAME3.0: Converging HPC and BD/AI
Satoshi Matsuoka (Tokyo Institute of Technology)
Nov. 14th Tue. 11:30AM - 12:00PM
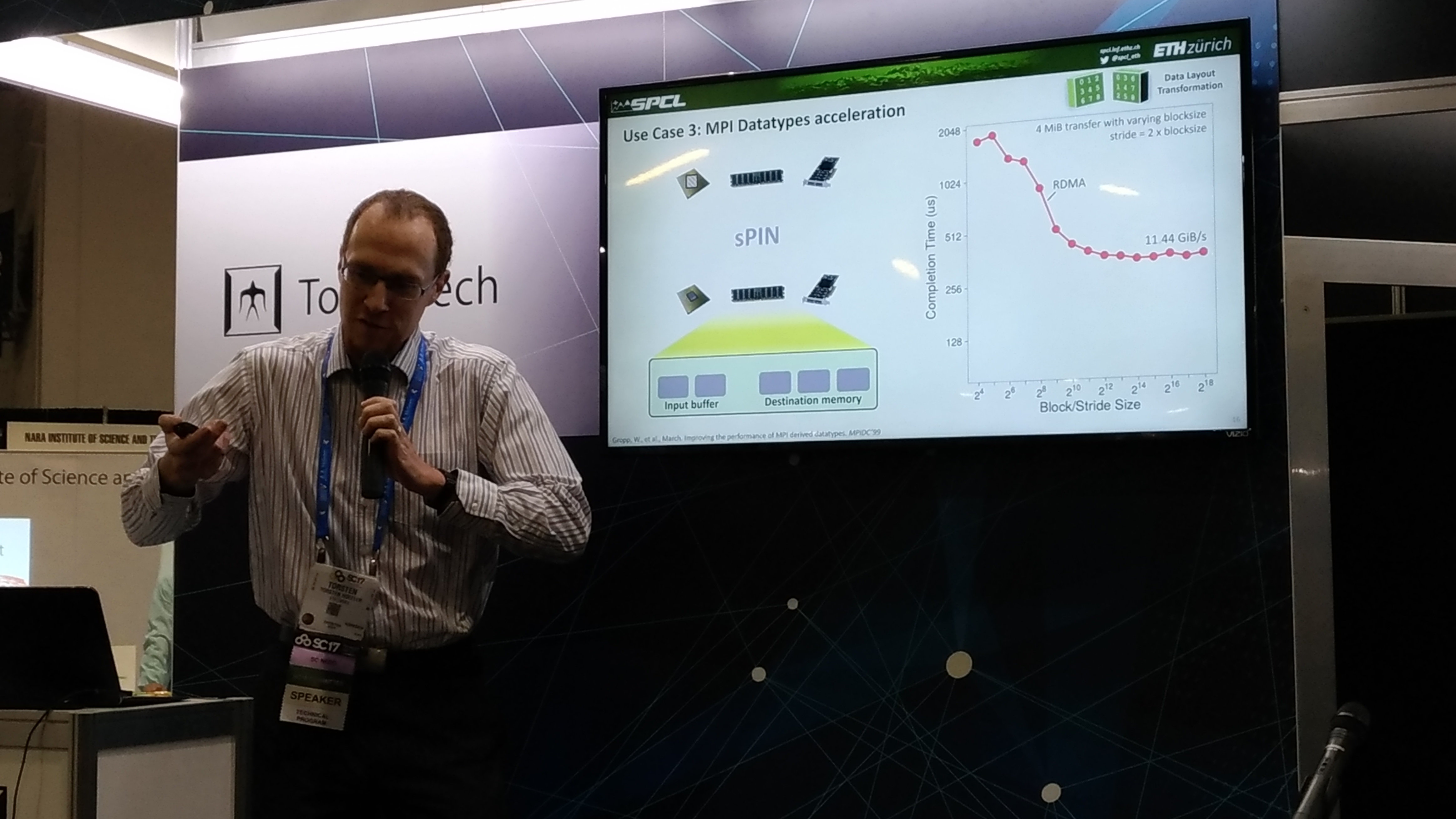
sPIN: High-performance Streaming Processing in the Network
Torsten Hoefler (Eidgenössische Technische Hochschule Zürich)
Nov. 14th Tue. 2:00PM - 2:30PM

Accelerated Deep Learning Advances in HPC
William Tang (Princeton University)
Nov. 14th Tue. 4:00PM - 5:00PM
TSUBAME3.0 Special Session
Hewlett Packard Enterprise, NVIDIA, Intel, DataDirect Networks
Nov. 15th Wed. 3:00PM - 3:30PM

Application Readiness Projects for the Summit Architecture
Tjerk Straatsma (Oak Ridge National Laboratory)
Abstracts of Booth Talk
| Title | Converging HPC and BD/AI: Tokyo Tech TSUBAME3.0 and AIST ABCI |
| Speaker | Satoshi Matsuoka (Tokyo Institute of Technology) |
| Abstract | The TSUBAME3 supercomputer at Tokyo Institute of Technology became online in Aug. 2017, and became the greenest supercomputer in the world on the Green 500 at 14.11 GFlops/W; the other aspect of TSUBAME3, is to embody various BYTES-oriented features to allow for HPC to BD/AI convergence at scale, including significant scalable horizontal bandwidth as well as support for deep memory hierarchy and capacity, along with high flops in low precision arithmetic for deep learning. TSUBAME3's technologies are commoditized to construct one of the world’s largest BD/AI focused open and public computing infrastructure called ABCI (AI-Based Bridging Infrastructure), hosted by AIST-AIRC (AI Research Center), the largest public funded AI research center in Japan, at 550 AI-Petaflops, with acceleration in I/O and other data-centric properties desirable for accelerating BD/AI, to be online 1H2018. |
| Title | sPIN: High-performance streaming Processing in the Network |
| Speaker | Torsten Hoefler (Eidgenössische Technische Hochschule Zürich) |
| Abstract | Optimizing communication performance is imperative for large-scale computing because communication overheads limit the strong scalability of parallel applications. Today’s network cards contain rather powerful processors optimized for data movement. However, these devices are limited to fixed functions, such as remote direct memory access. We develop sPIN, a portable programming model to offload simple packet processing functions to the network card. To demonstrate the potential of the model, we design a cycle-accurate simulation environment by combining the network simulator LogGOPSim and the CPU simulator gem5. We implement offloaded message matching, datatype processing, and collective communications and demonstrate transparent full-application speedups. Furthermore, we show how sPIN can be used to accelerate redundant in-memory filesystems and several other use cases. Our work investigates a portable packet-processing network acceleration model similar to compute acceleration with CUDA or OpenCL. We show how such network acceleration enables an eco-system that can significantly speed up applications and system services. |
| Title | Accelerated Deep Learning Advances in HPC |
| Speaker | Bill Tang (Princeton University) |
| Abstract |
Building the scientific foundations needed to deliver accurate predictions in key scientific domains of current interest can best be accomplished by engaging modern big-data-driven statistical methods featuring machine/deep learning (ML/DL). This exciting R&D approach is increasingly deployed in many scientific and industrial domains, such as the new Internet services economy and many other emerging examples. These techniques can be formulated and adapted to enable new avenues of data-driven discovery in key scientific applications areas such as the quest to deliver Fusion Energy – identified by the 2015 CNN “Moonshots for the 21st Century” series as one of 5 prominent grand challenges. An especially time-urgent and most challenging problem facing the development of a fusion energy reactor is the need to reliably predict and avoid large-scale major disruptions in magnetically-confined tokamak systems such as the EUROfusion Joint European Torus (JET) today and the burning plasma ITER device in the near future. Significantly improved methods of prediction with better than 95% predictive capability are required to provide sufficient advanced warning for disruption avoidance or mitigation strategies to be effectively applied before critical damage can be done to ITER -- a ground-breaking $25B international burning plasma experiment with the potential capability to exceed “breakeven” fusion power by a factor of 10 or more. This truly formidable task demands accuracy beyond the near-term reach of hypothesis-driven /”first-principles” extreme-scale computing (HPC) simulations that dominate current research and development in the field. Recent HPC-relevant advances in the deployment of deep learning recurrent nets have been demonstrated in exciting scaling studies of Princeton’s new Deep Learning Code -- "FRNN (Fusion Recurrent Neural Net) Code on modern GPU systems. This is clearly a “big-data” project in that it has direct access to the huge EUROFUSION/JET disruption data base of over a half-petabyte to drive these studies1. FRNN implements a distributed data parallel synchronous stochastic gradient approach with “Tensorflow”2 and “Theano” 3 libraries at the backend and MPI for communication. This deep learning software has recently demonstrated excellent scaling up to 6000 GPU's on Titan – enabled by a 2017 Oak Ridge Leadership Computing Facility (OLCF) Director’s Discretionary Award. This has enabled stimulating progress toward the goal of establishing the practical feasibility of using leadership class supercomputers to greatly enhance training of neural nets to enable transformational impact on key discovery science application domains such as Fusion Energy Science. Powerful systems targeted for near-future deployment of our deep learning software include: (1) Japan’s new “Tsubame 3” system with 3000 P-100 GPU’s; (2) Switzerland’s “Piz Daint” CRAY XC50 system with its 4500 P100 GPU’s; (2) Switzerland’s “Piz Daint” CRAY XC50 system with its 4500 P100 GPU’s; and (3) OLCF’S “Summit-Dev” system. Summarily, statistical Deep Learning software trained on very large data sets hold exciting promise for delivering much-needed predictive tools capable of accelerating scientific knowledge discovery in HPC. The associated creative methods being developed also has significant potential for cross-cutting benefit to a number of important application areas in science and industry. |
| Title | Application Readiness Projects for the Summit Architecture |
| Speaker | Tjerk Straatsma (Oak Ridge National Laboratory) |
| Abstract | The Oak Ridge Leadership Computing Facility (OLCF) in partnership with the IBM/NVIDIA Center of Excellence and scientific application developers is preparing a suite of scientific codes for its user programs. The Center for Accelerated Application Readiness (CAAR) projects are using an Early Access Power8+/Pascal system named SummitDev to prepare for the Power9/Volta system Summit. This presentation highlights achievements on this system, and the experience of the teams that will be a valuable resource for other development teams. |