Urgent Info
- There is no Urgent Info now.



GSIC
| Addr. | 2-12-1 O-okayama, Meguroku, Tokyo 152-8550 JAPAN |
| Contact this mail address. |
You are here
Preliminary report
Preliminary report within one month is required, after the user project completes the TSUBAME grand-challenge program. The project result in the preliminary report is opened to the public in this web page as below.
Their final report is also required within one year and opened to the public in "the list of adapted projects".
2012 Autumn, 2012 Spring, 2013 Spring
2012 Autumn adopted subject
Large-Eddy Simulation of Wind Blowing for a Wide Area of Tokyo with 1-m Resolution by using Lattice Boltzmann Method on TSUBAME 2.0
[Person in charge]
Takayuki Aoki - Professor, Tokyo Institute of Technology, GSIC
[Category]
Category A (all nodes)
A lot of tall buildings and complex structures in urban large cities make the air flow turbulent. In order to understand the detail of the airflow there, it is necessary to carry out large-scale CFD (Computational Fluid Dynamics) simulations. We have developed a CFD code based on LBM (Lattice Boltzmann Method). Since air flows in large cities are turbulent with a several-millions Reynolds number, a LES (Large-Eddy Simulation) model has to be introduced into the LBM equation. The dynamic Smagorinsky model is often used however it requires an average operation for a wide area to determine the model constant. Since it becomes huge overhead for large-scale computations, we applied the coherent-structure Smagorinsky model which does not take any spatial averages and is able to determine the model constant locally. The code is written in CUDA and the GPU kernel function is well tuned to achieve high performance on Fermi-core GPUs. By introducing the overlapping technique between the GPU-to-GPU communication and the GPU kernel computation, we have improved 30% for the large-scale computation. Although the LBM computation is essentially memory bound, we obtained fairly good performances in both the strong and the weak scalabilities. We achieved 149 TFLOPS in single precision, which is compatible with 15% of the peak performance of 1,000 GPUs. We used 4,032 GPUs for the computation with 10,080 × 10,240 × 512 mesh. By executing this large-scale computation, detailed winds behind buildings, so called "wind street" along a big street, the damage of typhoon and other will be revealed with much higher accuracy than before. The LES computation for the area 10km × 10km with 1-m resolution has never been done before in the world.

Figure Result of Wind Blowing in a Wide Area of Tokyo
Performance evaluation of large-scale graph processing benchmark, Graph500 with newly introduced graph kernel using highly scalable search method
[Person in charge]
Toyotaro Suzumura - Visiting Associate Professor, Tokyo Institute of Technology
[Category]
Category A (all nodes)
Graph500 is a new benchmark that ranks supercomputers by executing a large-scale graph search problem.
It does breadth-first searches (BFS) in undirected large graphs and the ranking results depend on the throughput in TEPS (Traversed Edges Per Second). We investigated optimal parameters for our Graph500 BFS implementation and found that our implementation can perform BFS faster than before. We run Graph500 benchmark with optimal parameters and achieved 431 GTEPS with the large graph, SCALE 35. We also run our optimized implementation for Single Source Shortest Path problem (SSSP), which is new kernel on Graph500 benchmark. We evaluated the performance and found that (a) 2D partitioning method for adjacency matrix is effective for SSSP as well as BFS, (b) Inter-process synchronization cost is large on computing SSSP.
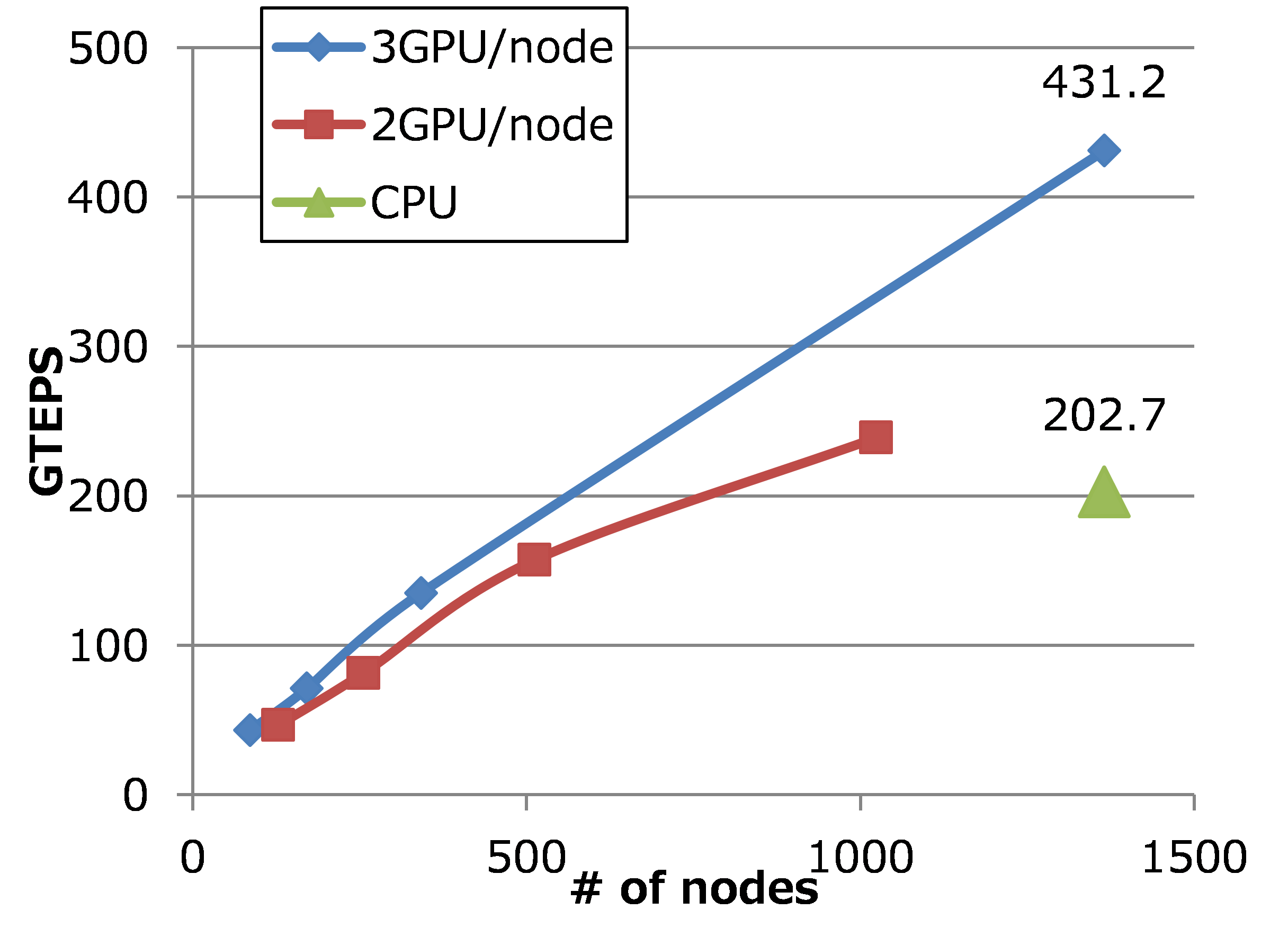
Figure Performance of Graph500 benchmark on TSUBAME2.0
2012 Spring adopted subject
Performance Evaluation of Large Scale Graph Processing Benchmark, Graph500 with Highly Scalable GPU Implementation
[Person in charge]
Toyotaro Suzumura - Visiting Associate Professor, Tokyo Institute of Technology
[Category]
Category A (all nodes)
Graph500 is a new benchmark that ranks supercomputers by executing a large-scale graph search problem.
It does breadth-first searches (BFS) in undirected large graphs and the ranking results depend on the throughput in TEPS (Traversed Edges Per Second). We developed CPU implementation and GPU implementation using our new efficient method for computing large distributed BFS based on 2D partitioning. In our grand challenge benchmark, we ran our implementations. Our CPU implementation can solve BFS for large-scale graph with 137 billion vertices and 2.2 trillion edges for 10.85 seconds with 1366 nodes and 2732 CPUs, which corresponds to 203 GTEPS. Our GPU implementation can solve BFS for the graph with 34.4 billion vertices and 550 billion edges for 1.73 seconds with 1366 nodes and 4096 GPUs.
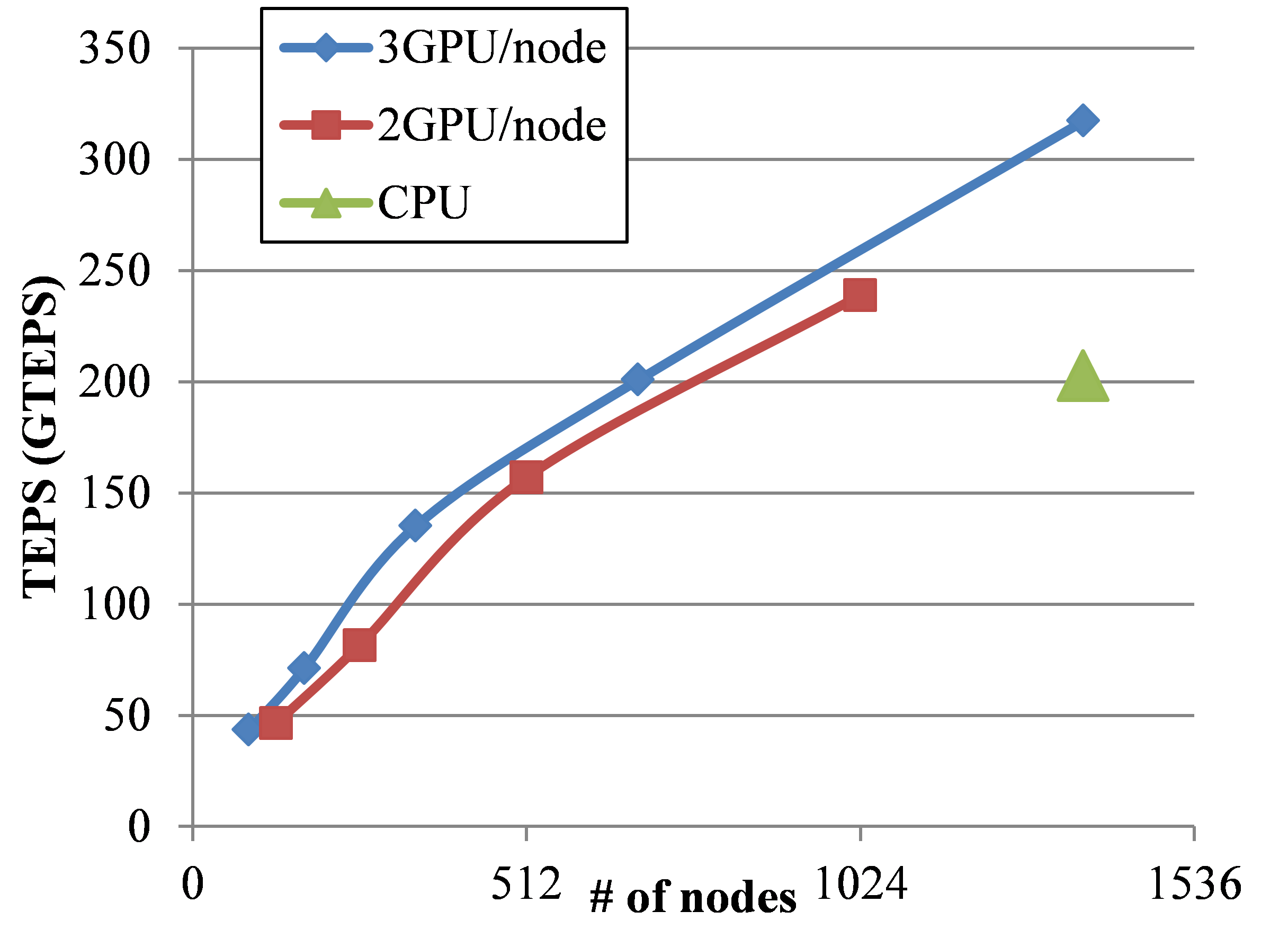
Figure Performance of Graph500 benchmark on TSUBAME2.0
Solving extremely large-scale semidefinite optimization problems via parallel computation of the interior-point method
[Person in charge]
Katsuki Fujisawa - Professor, Department of Industrial and Systems Engineering Chuo University
[Category]
Category A (all nodes)
Semidefinite Programming (SDP) is one of the most important problems in current research areas in optimization problems. It covers a wide range of applications such as combinatorial optimization, structural optimization, control theory, economics, quantum chemistry, sensor network location, data
mining, etc. Solving extremely large-scale SDP problems has significant importance for the current and future applications of SDPs. In 1995, Fujisawa et al. started the SDPA Project aimed for solving large-scale SDP problems with numerical stability and accuracy. SDPA is one of pioneers' codes to solve general SDPs. SDPARA is a parallel version of SDPA on multiple processors and distributed memory, which replaces two major bottleneck parts (the generation of the Schur complement matrix and its Cholesky
factorization) of SDPA by their parallel implementation. In this grand challenge, we accelerate this part by using massively parallel GPUs with much higher computation performance than CPUs. In order to achieve scalable performance with thousands of GPUs, we utilize high performance BLAS kernel coupled with optimization techniques to overlap computation(Figure 1), PCI-Express communication and MPI communication. In particular, SDPARA has been successfully applied on combinatorial optimization and truss topology optimization, the new version of SDPARA(7.5.0-G) on a large-scale super computer called
TSUBAME2.0 in Tokyo Institute of Technology has succeeded to solve the largest SDP problem(Figure 2) which has over 1.48 million constraints and make a new world record. Our implementation has also achieved 533 TFlops in double precision for the large-scale Cholesky factorization using 2,720 CPUs and 4,080 GPUs(Figure 3).
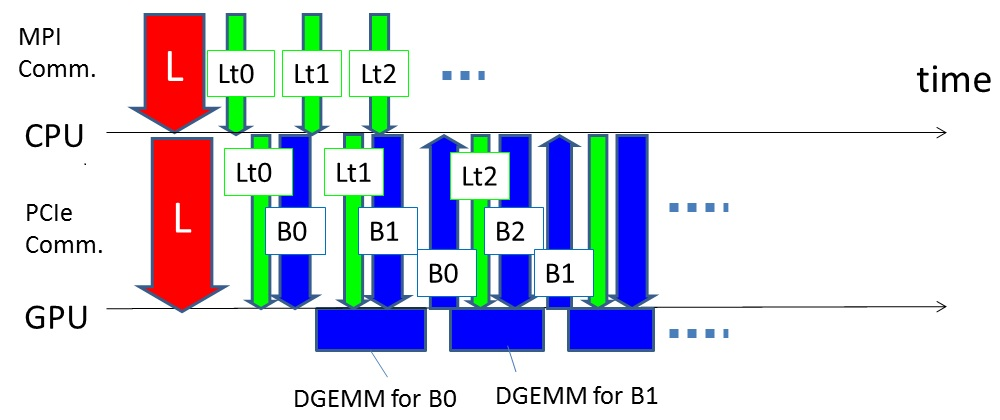
Figure 1 : GPU Computation, PCIe communication and MPI communication are overlapped
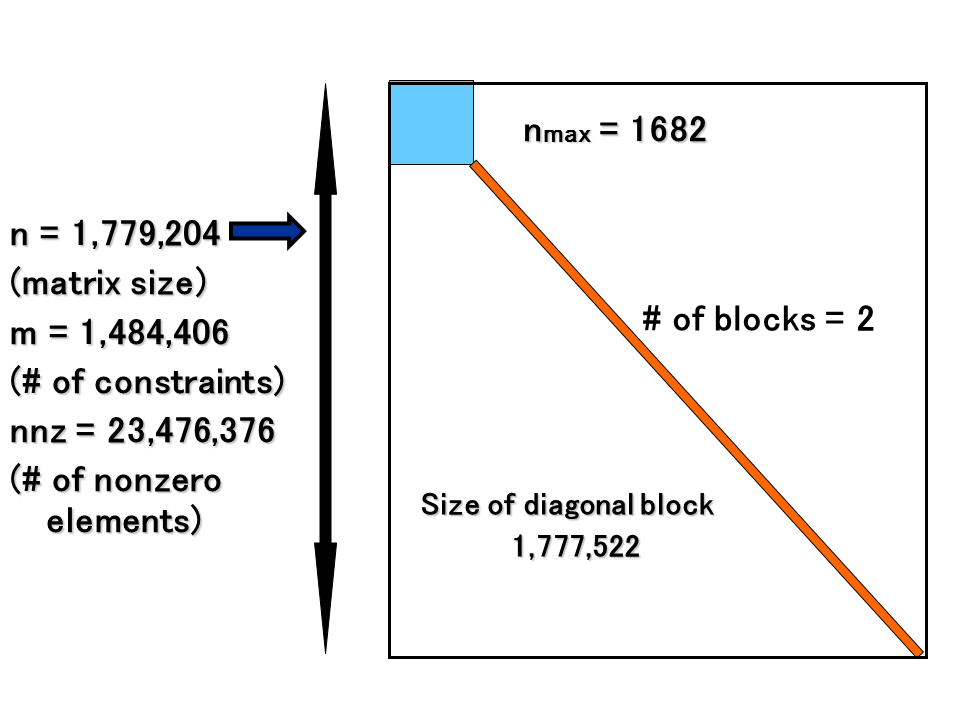
Figure 2 : The largest SDP problem and its block diagonal structure
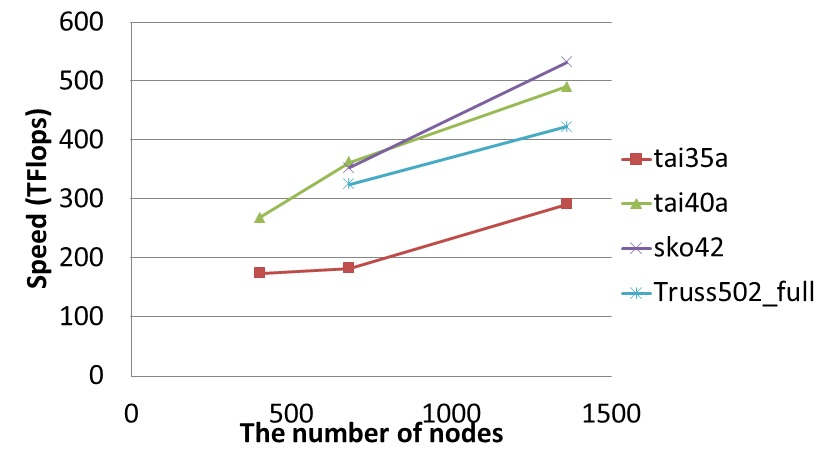
Figure 3 : Performance of GPU Cholesky factorization on the full TSUBAME2.0 system (up to 1,360nodes, 4,080GPUs)
2013 Spring adopted subject
Solving the Schrödinger Equation of Some Organic and Inorganic Molecules with Superparallel Computer TSUBAME
[Person in charge]
Hiroshi Nakatsuji - Director, Quantum Chemistry Research Institute
[Category]
Category B
The present purpose is to solve the Schrödinger equations of general organic molecules with the free complement - local Schrödinger equation (FC-LSE) method. To realize highly accurate Schrödinger level calculations of general organic molecules, the From Atom to Molecule (FATM) method were combined with the increasing exchange (iExg) method of antisymmetrization (HN, QCRI Report, June 2010) that has a clear order-N characteristics were first implemented. We could effectively use the TSUBAME supercomputer for both the developments of the methodology and programing and the actual calculations. Although the organic molecules applied here were not large, we could obtain highly accurate wave functions than those of ordinary quantum chemistry methods. We could also perform the test calculations of benzene molecule, whose application was not planned in the first proposal. In the timing test of the present program, a super-parallel efficiency was obtained but it might indicate the necessity of tuning for a single processor.
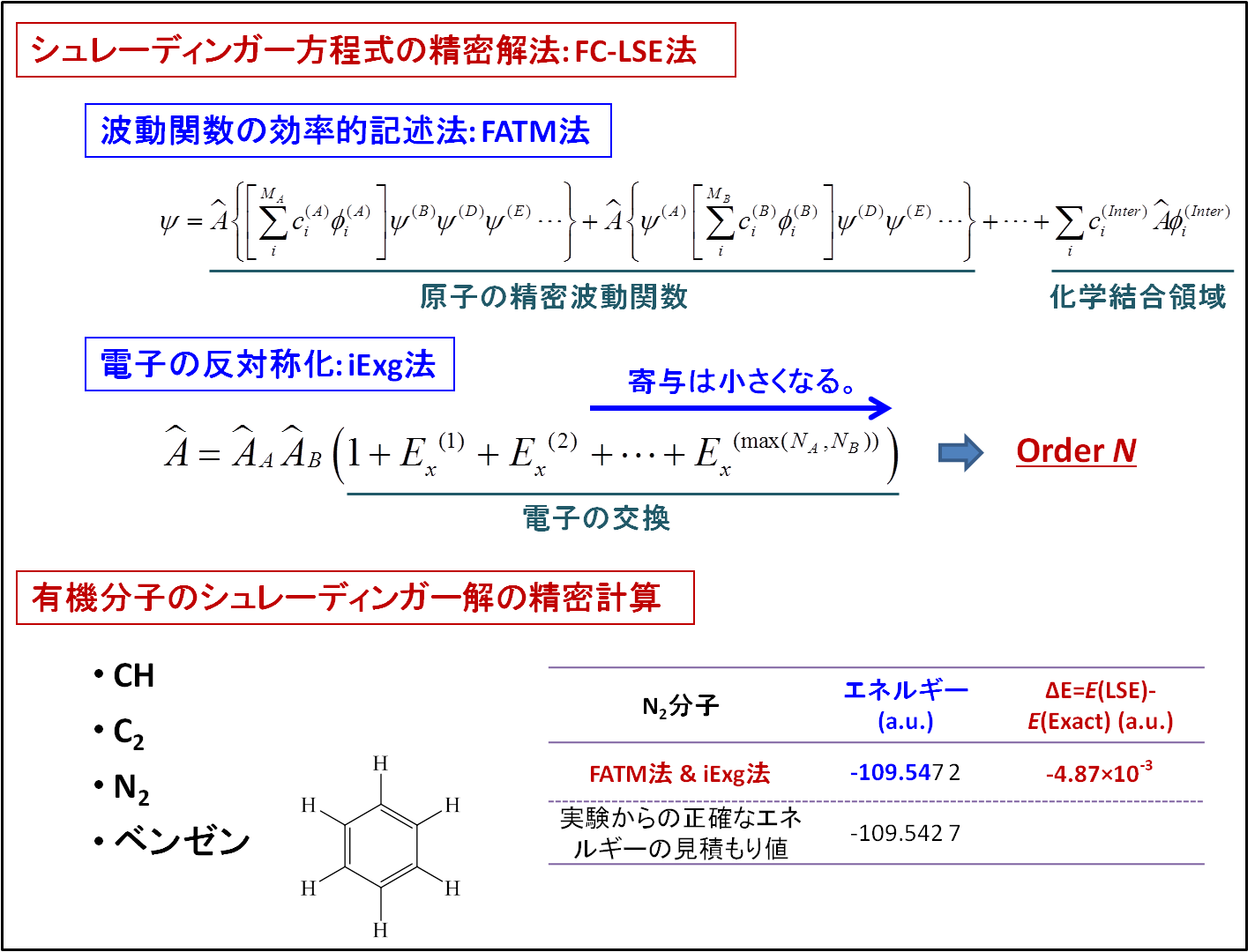
Figure Solving the Schrödinger equations of general organic molecules with the FC-LSE-iExg method
Development and Numerical Evaluation of High-Performance General Solver for Extremely Large-Scale Semidefinite Programming
[Person in charge]
Katsuki Fujisawa - Professor, Department of Industrial and Systems Engineering Chuo University
[Category]
Category A (all nodes)
The semidefinite programming (SDP) problem is one of the most central problems in mathematical optimization. The numerical results of solving large-scale SDP problems can provide useful information and solutions in many research fields. The primal-dual interior-point method (PDIPM) is one of the most powerful algorithms for solving SDP problems, and many research groups have employed it for developing software packages. However, two well-known major bottleneck parts i.e., the generation of the Schur complement matrix (SCM) and its Cholesky factorization exist in the algorithmic framework of PDIPM. SDP is relevant to a wide range of fields such as combinatorial optimization, structural optimization, control theory, quantum chemistry, and data mining; however, identification of a bottleneck part strongly depends on the problem size, the number of constraints, and the sparsity of the problem. We have developed a new version of SDPARA, which is a parallel implementation on multiples CPUs and GPUs for solving extremely large-scale SDP problems with over a million constraints.
SDPARA can automatically extract the unique characteristics from an SDP problem and identify the bottleneck. When the generation of SCM becomes a bottleneck part, SDPARA can attain high scalability using a large quantity of CPU cores and some techniques of processor affinity and memory interleaving (Figure 2 and 3). SDPARA can also perform parallel Cholesky factorization using thousands of GPUs and techniques to overlap computation and communication if an SDP problem has over a million constraints and Cholesky factorization constitutes a bottleneck part. We demonstrate that SDPARA is a high-performance general solver for SDPs in various application fields through numerical experiments on the TSUBAME 2.0 supercomputer, and we solved the largest SDP problem (which has over 2.33 million constraints)(Figure 1), thereby creating a new world record. Our implementation also achieved 1.018 PFlops in double precision for large-scale Cholesky factorization using 2,720 CPUs and 4,080 GPUs (Figure 4).
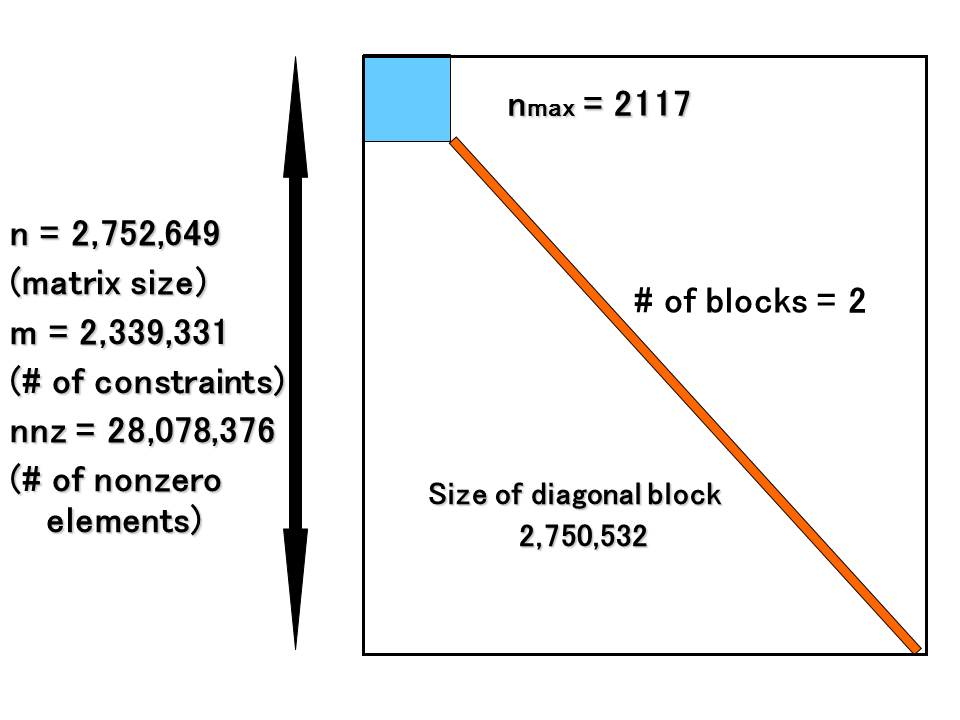
Figure 1 : The largest SDP problem and its block diagonal structure
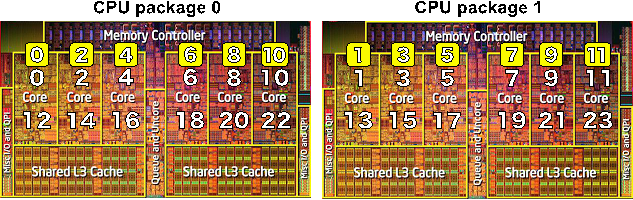
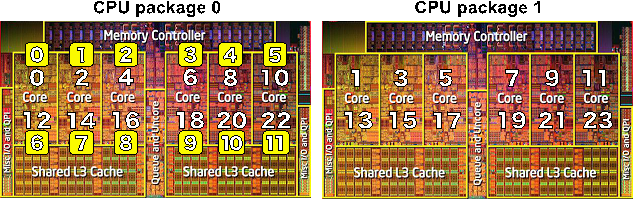
Figure 2 : CPU affinity policies: “scatter” and “compact”
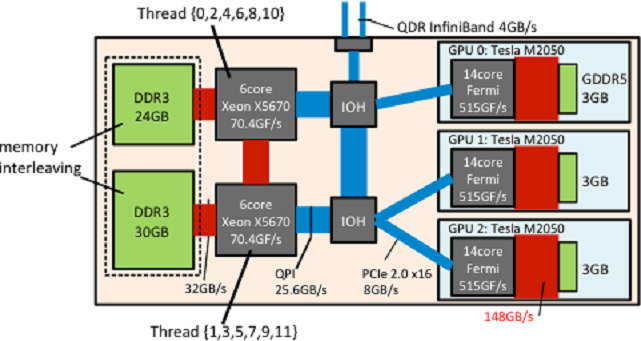
Figure 3 : Scatter-type affinity and memory interleaving for the HP SL390s G7 on TSUBAME2.0
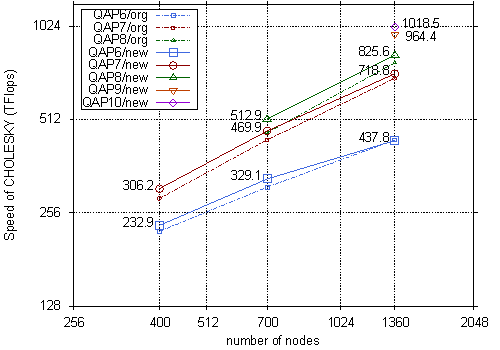
Figure 4 : Performance of GPU Cholesky factorization on the full TSUBAME2.0 system (up to 1,360nodes, 4,080GPUs)